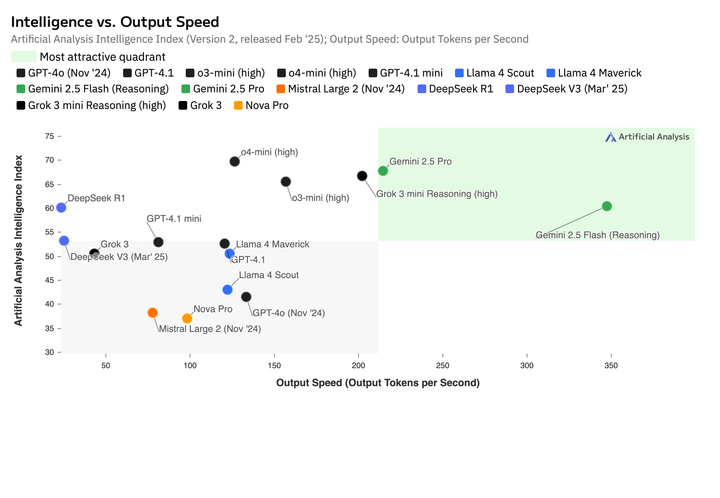
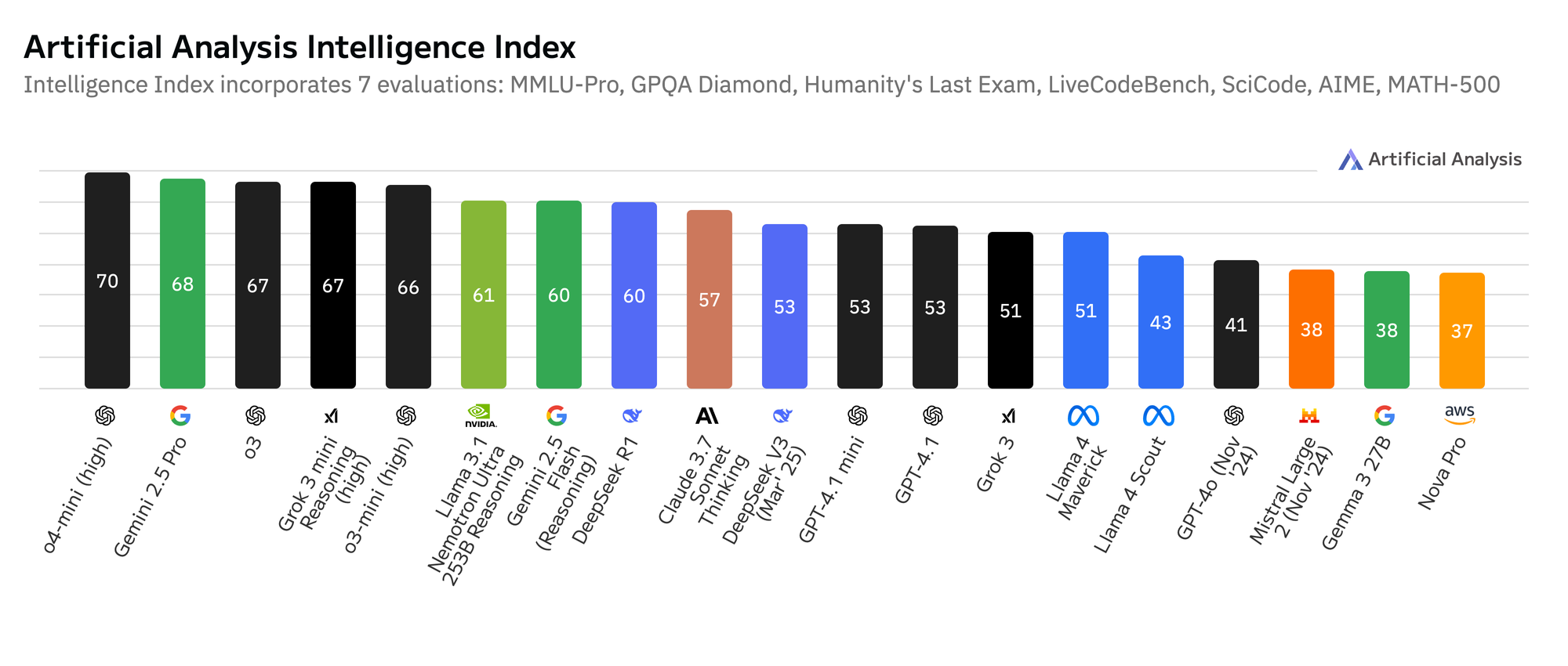
In den letzten Monaten habe ich intensiv zu KI recherchiert. Aktuelle Trends finden sich häufig auf YouTube. Diese Wissen hat sicher nicht die Halbwertszeit von anderen Platformen und es ist viel Schrott dabei. Das vorliegende Video ist auf den ersten Blick unspektakulär. Der Inhalt fasst aber vieles gut und prägnant zusammen. Ich nehme an, das Thema hat nicht nur für mich Relevanz, daher habe ich es auf Deutsch übersetzt und als Blog dargestellt.
Der Inhalt dieses Beitrags wurde mit Hilfe von KI-Tools erstellt. Dabei wurde das Transkript eines Videos auf Deutsch übersetzt, eine Zusammenfassung generiert und Tabellen in Markdown-Format aus Bildschirmfotos erstellt. Die Überarbeitung des Textes und die Formatierung erfolgte ohne KI. Zurzeit ist noch viel Handarbeit nötig, die Fortschritte über die letzen Monate sind aber gewaltig.
Dieses Video hat mich darin bestärkt, die eigene Hardware aufzubessern. Siehe hier:
Quelle
Why Smart Entrepreneurs Are Ditching Cloud Al and
Going Local (While Everyone Else Gets Left Behind)
By: Ilmacademy.com
Zusammenfassung
Preston Rodes spricht im YouTube Video vom 8.4.2025 über einen bedeutenden Wandel im Bereich der künstlichen Intelligenz, der als 'grossartige KI-Migration' bezeichnet wird, bei der Unternehmen und Einzelpersonen von Cloud-basierten KI-Lösungen auf lokale Implementierungen umsteigen. Dieser Trend wird durch drei Hauptfaktoren vorangetrieben:
- die verbesserte Leistung von Open-Source-KI-Modellen
- Fortschritte in der Hardware-Effizienz
- Verbesserungen bei den Techniken zur Modellquantisierung
Die zunehmende Leistungsfähigkeit lokaler Modelle, kombiniert mit den Nachteilen von Cloud-KI wie Zensur, Kosten und Compliance-Problemen, macht lokale KI zu einer attraktiveren und flexibleren Option. Der Author unterstreicht, dass die Fähigkeit, spezialisierte kleinere Modelle für bestimmte Aufgaben zu verwenden und eine Multi-Modell-Architektur zu implementieren, erhebliche Effizienz- und Kostenvorteile bietet, was zu einem Wettbewerbsvorteil führt.
DIE GROSSE KI-MIGRATION.
Warum kluge Unternehmer Cloud AI aufgeben und auf lokale Lösungen setzen (während alle anderen zurückbleiben).
In der KI findet gerade ein massiver Wandel statt, dessen Beweise unbestreitbar sind.
Ich erinnere mich noch genau an den Moment, als mir klar wurde, dass sich alles ändern würde. Ich analysierte den GitHub-Stars-Trend für Ollama und sah, wie er in wenigen Monaten von 5.000 auf über 50.000 anstieg. In der Zwischenzeit hatte DeepSeek sein Open-Source-Modell veröffentlicht, das bei mehreren Benchmarks mit GPT-4 mithalten konnte. Und China beschleunigte seine Investitionen in Open Source AI.
Das waren keine Einzelfälle. Es waren Datenpunkte in einem Muster, das unmöglich zu ignorieren war:
Die Zukunft der KI liegt nicht in der Cloud. Sie läuft auf Ihrer eigenen Hardware.
Drei konvergierende Kräfte führen den Wendepunkt herbei.
Das ist keine Spekulation. Die Daten erzählen eine klare Geschichte.
Drei technologische Kräfte konvergieren gerade, um eine fundamentale Verschiebung in der Art und Weise zu bewirken, wie KI eingesetzt und genutzt wird:
- Open Source Modell Performance
- Durchbrüche bei der Hardware-Effizienz
- Fortschritte bei der Modellquantisierung
Lassen Sie mich darlegen, was die Forschung tatsächlich zeigt...
Die Open Source Qualitätskonvergenz
Die Kluft zwischen proprietären und Open-Source-Modellen ist in einem Tempo geschrumpft, das selbst Brancheninsider schockiert hat:
| Jahr | Open-Source-Modell | Parameter | Benchmark (MMLU) | Proprietäres Äquivalent |
|---|---|---|---|---|
| 22 | Bloom | 176B | 45.5% | GPT-3 (53.9%) |
| 23 | Llama 2 | 70B | 68.9% | GPT-3.5 (70.0%) |
| 24 | DeepSeek | 67B | 75.3% | GPT-4 (77.4%) |
| 24 | Llama 3 | 70B | 76.0% | GPT-4 (77.4%) |
Diese Daten erzählen eine unmissverständliche Geschichte:
die Qualitätslücke ist tatsächlich verschwunden.
Und das ist nicht nur theoretische Benchmark-Leistung. Es übersetzt sich direkt in Geschäftsanwendungen.
Ich habe systematische Vergleiche durchgeführt bei:
- Marketing-Content-Generierung
- Kundenservice-Antworten
- Datenanalyse und -zusammenfassung
- Code-Generierung
- Dokumentenanalyse
In Blindtests mit tatsächlichen Geschäftsnutzern waren die lokalen Modelle in über 80 % der Fälle nicht von Cloud-Versionen zu unterscheiden.
Die Hardware-Effizienz-Revolution
"Aber braucht man dazu nicht massive GPU-Cluster, um diese Modelle auszuführen?"
Das stimmte früher. Nicht mehr.
Die Fortschritte bei der Modelleffizienz waren atemberaubend:
| Jahr | Model-Grösse | Benötigte Hardware | Inference Speed |
|---|---|---|---|
| 22 | 7B parameters | NVIDIA A100 ($$$$) | 5-10 tokens/sec |
| 23 | 7B parameters | RTX 3090 ($$$) | 15-20 tokens/sec |
| 24 | 7B parameters | MacBook M2 ($$) | 20-30 tokens/sec |
Dies ist keine geringfügige Verbesserung. Es ist eine grundlegende Verschiebung dessen, was möglich ist.
Vor zwei Jahren erforderte die lokale Ausführung eines guten Sprachmodells:
- Einen dedizierten Server für über 10.000 US-Dollar
- Spezialisiertes ML-Wissen
- Ständige Wartung
Heute können Sie produktionsreife Modelle ausführen auf:
- Einem Laptop, den Sie bereits besitzen
- Mit Ein-Klick-Installation
- Ohne technische Erfahrung
Der Trend ist eindeutig.
Der Quantisierungs-Durchbruch
Hier wird es richtig interessant.
Der Durchbruch, der all dies ermöglicht? Quantisierung.
Quantisierung ist der Prozess der Umwandlung von Modellgewichten von hoher Präzision (32-Bit Floating Point) in niedrigere Präzisionsformate (8-Bit, 4-Bit oder sogar 3-Bit).
Die Ergebnisse sprechen für sich:
| Präzision | Dateigrösse | Speicherverbrauch | Geschwindigkeit | Qualitätsverlust |
|---|---|---|---|---|
| FP32 (Original) | 140 GB | 140 GB | 1x | 0% |
| FP16 | 70 GB | 70 GB | 1.3x | ~0% |
| INT8 | 35 GB | 35 GB | 1.8x | ~2% |
| INT4 | 17.5 GB | 17.5 GB | 2.5x | ~5% |
| GGUF Q4_K_M | 8.5 GB | 10 GB | 3x | ~5-7% |
Das bedeutet, ein Modell, das einst 140 GB RAM benötigte, kann nun mit minimalem Qualitätsverlust in weniger als 10 GB ausgeführt werden.
Und der Innovationszyklus verlangsamt sich nicht – er beschleunigt sich. Monatlich tauchen neue Quantisierungstechniken auf.
Die Multi-Modell-Strategie, die alles verändert
Einer der leistungsstärksten Aspekte der lokalen KI, über den niemand spricht?
Die Fähigkeit, verschiedene spezialisierte Modelle für verschiedene Aufgaben zu verwenden.
Bei Cloud AI sind Sie im Allgemeinen auf ein Modell für alles beschränkt.
Mit lokaler Bereitstellung können Sie verwenden:
- Ein 3B-Parameter-Modell für Klassifizierung und einfache Aufgaben
- Ein 7B-Modell für kreative Inhalte und Kundenservice
- Ein 13B-Modell für komplexes Denken und Analyse
- Ein 70B-Modell für spezialisierte Expertise, wenn benötigt
Dies schafft einen massiven Effizienzvorteil.
Ich habe einer Marketingagentur geholfen, ein System zu implementieren mit:
- Mistral 7B für Copywriting (läuft auf CPU)
- DeepSeek Coder für Automatisierungsskripte (läuft auf GPU)
- Llama 3 70B für Strategieentwicklung (läuft auf GPU)
Sie wählen das richtige Modell für jede Aufgabe automatisch aus. Das Ergebnis?
- 87 % Kostenreduktion im Vergleich zur Cloud API
- 34 % schnellere durchschnittliche Antwortzeit
- 100 % Beseitigung von Fähigkeitseinschränkungen
Der selektive Bereitstellungsansatz ist etwas, das Cloud APIs einfach nicht erreichen können.
Die Hugging Face Suchdaten, die jeder übersieht
Sehen Sie sich an, was bei Hugging Face (dem GitHub für KI-Modelle) passiert:
| Monat | Downloads lokaler LLMs | Wachstumsrate | Beliebteste Modelle |
|---|---|---|---|
| Jan 2023 | 1.2M | - | Bloom, GPT-J |
| Jan 2024 | 37M | 2983% | Llama 2, Mistral |
| Apr 2024 | 108M | 192% | DeepSeek, Llama 3 |
Die Adoptionskurve ist nicht linear – sie ist exponentiell.
Und die Suchtrends erzählen eine noch interessantere Geschichte:
Top 5 Hugging Face Suchbegriffe (letzte 90 Tage):
- "Quantization"
- "local llm"
- "RAG"
- "Fine-tuning"
- "multi-model"
Das ist nicht nur das Interesse von Forschern. Es sind Entwickler und Unternehmen, die diese Technologien aktiv implementieren.
Die Cloud AI Einschränkungen, die niemand zugibt
Sprechen wir über die Einschränkungen von Cloud AI, die die meisten Anbieter nicht zugeben.
Problem 1: Die Realität der Zensur
Jedes Unternehmen stösst irgendwann auf das, was ich die "Fähigkeitsmauer" bei Cloud AI nenne.
Hier sind reale Szenarien, denen Unternehmen täglich begegnen:
| Geschäftsbedarf | Cloud AI Antwort | Lokale KI Antwort |
|---|---|---|
| "Analysieren Sie den Marketingansatz unseres Konkurrenten" | "Ich kann bei der Wettbewerbsanalyse, die verwendet werden könnte, nicht helfen, um..." | Bietet detaillierte Analyse |
| "Schreiben Sie überzeugende Verkaufstexte für unser Abnehmprogramm" | "Es tut mir leid, aber ich kann keine Inhalte zur Förderung von Gewichtsverlust erstellen, da dies in eine sensible Kategorie fällt..." | Erstellt effektive Verkaufstexte |
| "Helfen Sie uns, unsere Preisstrategie zur Gewinnmaximierung zu optimieren" | "Ich kann allgemeine Preisinformationen bereitstellen, aber nicht helfen, die Preisgestaltung zur Gewinnmaximierung zu optimieren, da dies als... angesehen werden könnte." | Liefert spezifische Preisstrategien |
Das sind keine Einzelfälle. Das sind alltägliche Geschäftsbedürfnisse, die Cloud AI zunehmend zu adressieren sich weigert.
Problem 2: Die Kostenstruktur, die den Erfolg bestraft
Das Preismodell für Cloud AI ist grundlegend fehlerhaft:
| Nutzungsstufe | Cloud AI Monatskosten | Lokale KI Monatskosten | Einsparungen |
|---|---|---|---|
| Leicht (1M Token) | $20 | $20 (Strom) | Minimal |
| Mittel (10M Token) | $200 | $20 (Strom) | 90% |
| Schwer (100M Token) | $2.000 | $25 (Strom) | 99% |
| Unternehmen (1B Token) | $20.000 | $100-300 (Strom + Hardware-Abschreibung) | 99%+ |
Mit zunehmender KI-Nutzung skalieren die Cloud-Kosten linear, während die lokalen Kosten nahezu konstant bleiben.
Dies schafft einen perversen Anreiz: Je erfolgreicher Ihre KI-Implementierung, desto höher werden Sie mit Kosten bestraft.
Problem 3: Der Compliance-Albtraum
Für regulierte Branchen wird Cloud AI zunehmend problematisch:
| Branche | Regulierung | Cloud AI Problem | Lokale KI Lösung |
|---|---|---|---|
| Gesundheitswesen | HIPAA | Patientendaten in Prompts verletzen PHI-Regeln | Daten verlassen nie Ihre Infrastruktur |
| Finanzen | GLBA/PCI | Finanzdaten von Kunden können nicht an Dritte gesendet werden | Volle Datensouveränität |
| Recht | Mandanten-geheimnis | Bedenken hinsichtlich des Mandantengeheimnisses bei der Verarbeitung durch Dritte | Volle Kontrolle über den Informationsfluss |
| Bildung | FERPA | Studentendatenschutz unvereinbar mit Cloud-Bedingungen | Verarbeitung vor Ort wahrt Compliance |
Ein Healthcare-Kunde musste eine Cloud AI-Implementierung im Wert von 300.000 US-Dollar aufgeben, nachdem das Compliance-Team feststellte, dass sie gegen die Anforderungen zum Schutz von Patientendaten verstoss.
Sie wechselten zu einer lokalen Bereitstellung für insgesamt weniger als 50.000 US-Dollar.
Der Modellgrössen-Trend, den jeder verstehen muss
Hier ist ein kritischer Trend, der direkt dem widerspricht, was Cloud AI-Anbieter Sie glauben machen wollen:
Grössere Modelle sind nicht immer besser für spezifische Aufgaben.
Die Forschung zeigt zunehmend deutlich: spezialisierte kleinere Modelle übertreffen oft allgemeinere grössere Modelle für spezifische Geschäftsanwendungsfälle.
| Modellgrösse | Allgemeine Leistung | Spezialisierte Aufgabenleistung | Inferenzkosten |
|---|---|---|---|
| 70B+ | Ausgezeichnet | Gut | Sehr Hoch |
| 13B | Sehr Gut | Ausgezeichnet (wenn spezialisiert) | Moderat |
| 7B | Gut | Ausgezeichnet (wenn spezialisiert) | Niedrig |
| 3B | Ausreichend | Sehr Gut (wenn spezialisiert) | Sehr Niedrig |
Das erklärt, warum wir so viele Unternehmen sehen, die einen Multi-Modell-Ansatz verfolgen:
- Verwendung kleinerer, spezialisierter Modelle für Routineaufgaben
- Verwendung mittelgrosser Modelle für allgemeine Arbeit
- Reservierung grösserer Modelle nur für komplexes Denken
Cloud-Anbieter haben einen finanziellen Anreiz, Sie dazu zu drängen, ihre grössten, teuersten Modelle für alles zu verwenden.
Mit lokaler Bereitstellung können Sie das Modell an die Aufgabe anpassen – das schafft massive Effizienzgewinne.
Die "Richtiges Modell für die richtige Aufgabe"-Matrix
Eine meiner wichtigsten Erkenntnisse war, dass verschiedene Modelle in verschiedenen Geschäftsfunktionen hervorragend sind:
| Geschäftsfunktion | Empfohlener Modelltyp | Grössenbereich | Beispielmodelle |
|---|---|---|---|
| Kundensupport | Anweisungsoptimiert, konversationell | 7-13B | Mistral, Llama 3 |
| Inhaltserstellung | Kreative Textgenerierung | 7-13B | Llama 3, DeepSeek |
| Datenanalyse | Starke Denkfähigkeiten | 13-70B | DeepSeek, Llama 3 70B |
| Code-Generierung | Code-spezialisiert | 7-13B | DeepSeek Coder, CodeLlama |
| Dokumentenverarbeitung | Kontextfenster optimiert | 7-13B | Claude 3 Haiku, Llama 3 |
Diese selektive Bereitstellung ist bei den meisten Cloud-Diensten, bei denen Sie an ein Modell für alles gebunden sind, unmöglich.
Die Fähigkeit, das richtige Modell für jede spezifische Aufgabe auszuwählen, ist ein Game-Changer für Effektivität und Kosten.
Zwei Kategorien von KI-gestützten Unternehmen entstehen
Mit fortschreitendem Wandel sehe ich, wie sich Unternehmen in zwei verschiedene Kategorien aufteilen:
Die KI-Souveränen
Diese Organisationen betreiben ihre eigenen Modelle, passen die Fähigkeiten an ihre spezifischen Bedürfnisse an, setzen spezialisierte Modelle für verschiedene Aufgaben ein und behalten die vollständige Datenkontrolle. Merkmale:
- 70-99% niedrigere KI-Betriebskosten
- Vollständige Freiheit von Inhaltsbeschränkungen
- Volle Datenprivatsphäre und -sicherheit
- Möglichkeit zur Feinabstimmung auf ihr spezifisches Domain
- Massgeschneiderte Fähigkeiten, die ihre Konkurrenten nicht erreichen können
Die KI-Abhängigen
Diese Organisationen bleiben an Cloud-Anbieter gebunden, zahlen pro-Token-Gebühren, die mit der Nutzung skalieren, kämpfen mit zunehmenden Einschränkungen und senden ihre sensiblen Daten an Dritte. Merkmale:
- Kontinuierlich steigende KI-Kosten
- Wachsende Frustration mit Fähigkeitseinschränkungen
- Zunehmende Workarounds für Einschränkungen
- Wettbewerbsnachteil, da Einschränkungen verschärft werden
- Anfälligkeit für Preisänderungen
Die fortschrittlichen Systeme, die heute gebaut werden
Während die meisten Unternehmen immer noch versuchen, Cloud AI dazu zu bringen, ihre Marketingtexte zu genehmigen, bauen zukunftsorientierte Unternehmen bemerkenswerte Systeme mit lokaler KI:
Multi-Agenten-Architekturen
Mehrere spezialisierte KI-Agenten arbeiten zusammen an komplexen Geschäftsprozessen: [Customer Query] → [Classifier Agent] → [Specialized Agent 1-5] → [Response Agent] → [Customer]
Diese Systeme bewältigen komplexe Workflows ohne Pro-Token-Kosten und mit vollständiger Anpassung.
Feinabgestimmte Domain-Spezialisten
Modelle, die an spezifische Geschäftsbereiche angepasst sind und fogendes verstehen:
- Branchenspezifische Terminologie
- Produktkataloge des Unternehmens
- Markenstimme und -stil
- Historische Kundeninteraktionen
- Wettbewerbslandschaft
Diese Modelle erreichen in spezifischen Bereichen eine Leistung, die allgemeine Modelle nicht erreichen können.
Durch Reasoning verbesserte Systeme
Fortgeschrittene Implementierungen, die mehrere Modelle für optimale Leistung kombinieren:
[Query] → [Small Model (classification)] → [Medium Model (generation)] → [Large Model (verification)]
Dieser gestaffelte Ansatz maximiert die Effizienz bei gleichzeitiger Aufrechterhaltung der Qualität.
Die Adoptionskurve für lokalen KI
Wir können genau abbilden, wo wir uns auf der Technologie-Adoptionskurve befinden:
Early Adopters ↔ Early Majority ↔ Late Majority ↔ Laggards [YOU ARE HERE]
Gerade jetzt befinden wir uns im Übergang von den Early Adopters zur Early Majority.
Genau hier entstehen die bedeutendsten Wettbewerbsvorteile:
- Wissen und Expertise sind noch wertvoll
- Die Implementierung ist zugänglich, aber noch nicht kommodifiziert
- Das Kosten-Nutzen-Verhältnis ist äusserst günstig
- First-Mover-Vorteile sind erheblich
Bis nächstes Jahr wird dies Mainstream sein. Das Zeitfenster für bedeutende Vorteile ist jetzt.
Der Implementierungs-Fahrplan, der tatsächlich funktioniert
Basierend auf Dutzenden erfolgreicher Implementierungen ist dies der Ansatz, der konsistent Ergebnisse liefert:
Phase 1: Modellauswahl & Test (Woche 1)
- Ollama oder ähnlichen lokalen Runner deployen
- 3-5 verschiedene Modelle für Ihre spezifischen Anwendungsfälle testen
- Benchmark gegen Ihre aktuelle Cloud-Lösung durchführen
- Die optimalen Modelle für verschiedene Aufgaben identifizieren
Phase 2: Initiale Implementierung (Wochen 2-3)
- Ausgewählte Modelle für eine spezifische Geschäftsfunktion deployen
- Leistung, Kosten und Fähigkeitsverbesserungen dokumentieren
- Relevante Teammitglieder schulen
- Standardarbeitsanweisungen erstellen
Phase 3: Skalierte Bereitstellung (Monate 1-2)
- Auf zusätzliche Geschäftsfunktionen ausweiten
- Multi-Modell-Architektur implementieren, wo angemessen
- Mit bestehenden Tools und Workflows integrieren
- Überwachungs- und Managementprozesse entwickeln
Phase 4: Fortgeschrittene Optimierung (Monat 3+)
- Feinabstimmung für domain-spezifische Leistung explorieren
- RAG (Retrieval Augmented Generation) für Wissensintegration implementieren
- Proprietäre Systeme für Wettbewerbsvorteile entwickeln
- Nachhaltigkeits- und Skalierungspläne erstellen
Dieser Ansatz minimiert das Risiko und maximiert gleichzeitig die Geschwindigkeit zum Wert.
Die Hardware-Realität, die alles verändert
hat Die Hardware-Anforderungen sind auf ein Niveau gesunken, das die meisten Unternehmen problemlos bewältigen können:
| Modellgrösse | Hardwareanforderung 2023 | Hardwareanforderung 2024 |
|---|---|---|
| 7B | Dedizierte GPU | Moderner CPU (Apple M-Serie, aktuelle Intel/AMD) |
| 13B | High-End GPU (RTX 3090+) | Mid-Range GPU (RTX 3060+) oder M2 Ultra |
| 70B | Mehrere High-End GPUs | Einzelne High-End GPU (RTX 4090 oder ähnliches) |
Viele Unternehmen können effektive KI-Systeme auf Hardware ausführen, die sie bereits besitzen.
Für diejenigen, die ein Upgrade benötigen, sind die Kosten minimal im Vergleich zu den laufenden Cloud-Gebühren:
| Unternehmensgrösse | Typische Hardwareinvestition | Cloud-Äquivalente Kosten | ROI Zeitrahmen |
|---|---|---|---|
| Klein | $3.000-5.000 | $1.000-2.000/Monat | 2-5 Monate |
| Mittel | $10.000-20.000 | $5.000-10.000/Monat | 2-4 Monate |
| Unternehmen | $50.000-100.000 | $25.000-100.000/Monat | 1-4 Monate |
Der ROI (return of investment) wird nicht in Jahren gemessen. Er wird in Monaten oder sogar Wochen gemessen.
Die Datenschutz-Implikationen, die jeder verstehen sollt
Der Datenschutzaspekt von Cloud AI ist weitaus ernster, als die meisten Unternehmen erkennen:
Jede Abfrage, die Sie an Cloud AI senden, ist potenziell:
- Unbegrenzt gespeichert
- Einsehbar durch Mitarbeiter dieser Unternehmen
- Wird zum Training zukünftiger Modelle verwendet
- Gegenstand rechtlicher Offenlegung
- Anfällig für Datenlecks
| Datentyp | Cloud AI Risiko | Lokaler KI Vorteil |
|---|---|---|
| Strategische Pläne | Könnten die KI von Konkurrenten trainieren | Vollständig privat |
| Kundeninformationen | Potenzielle Verstösse gegen Vorschriften | Volle Datensouveränität |
| Produktentwicklung | Anfälligkeit für IP-Diebstahl | In Ihren Systemen enthalten |
| Finanzanalyse | Offenlegung sensibler Daten | Keine Datenübertragung |
| Wettbewerbsanalyse | Strategie-Leckage | Vollständig enthalten |
Mit lokaler Bereitstellung verlassen Ihre Daten niemals Ihre Infrastruktur.
Was ich beim Helfen von Unternehmen bei diesem Übergang gelernt habe
Nachdem ich Dutzende von Organisationen durch diesen Wandel geführt habe, sind hier die wichtigsten Lektionen:
- Beginnen Sie mit einer systematischen Modellevaluation. Verschiedene Modelle sind bei verschiedenen Aufgaben hervorragend, und das Finden des richtigen Modells macht einen riesigen Unterschied.
- Implementieren Sie eine Multi-Modell-Strategie. Die Verwendung spezialisierter Modelle für verschiedene Aufgaben schafft enorme Effizienz- und Leistungssteigerungen.
- Konzentrieren Sie sich zuerst auf eine Geschäftsfunktion. Komplette Transformation kann überwältigend wirken. Das Beginnen mit einem einzigen, hochkarätigen Anwendungsfall schafft Dynamik.
- Dokumentieren Sie alles. Side-by-Side-Vergleiche, Kostenanalysen und Fähigkeitsunterschiede schaffen aussagekräftige Beweise für eine erweiterte Adoption.
- Beziehen Sie Skeptiker frühzeitig ein. Die widerständigsten Teammitglieder werden oft zu den stärksten Fürsprechern, wenn sie die Ergebnisse aus erster Hand sehen.
Die Zukunft ist bereits da – sie ist nur ungleich verteilt
Wie William Gibson bekanntlich sagte: "Die Zukunft ist bereits da – sie ist nur noch nicht gleichmässig verteilt."
Genau da stehen wir mit der lokalen KI-Bereitstellung.
Einige Unternehmen arbeiten bereits mit Fähigkeiten, die ihre Konkurrenten für unmöglich halten.
Einige Teams erstellen, analysieren Daten und bedienen Kunden bereits mit Tools, die andere monate- oder jahrelang nicht entdecken werden.
Einige Unternehmer haben ihre KI-Kosten bereits um 95 % gesenkt und gleichzeitig die Fähigkeiten um 200 % gesteigert.
Die Technologie ist verfügbar. Die Implementierung ist zugänglich. Die Ergebnisse sind bewiesen.
Die einzige Frage ist: Auf welcher Seite dieser Kluft wird Ihr Unternehmen stehen?

