Video
Heute ist ein Video von Jan-Keno Janssen von c't 3003 auf YouTube erschienen. Er vergleicht verschiedene LLMs auf lokaler Hardware.
Zusammenfassung mit Obsidian Copilot Plugin
- Lokale KI‑Modelle können in hoher Geschwindigkeit auf dem eigenen Rechner laufen und erreichen teilweise Ergebnisse, die mit kommerziellen Diensten wie ChatGPT oder Claude vergleichbar sind.
- Für das lokale Ausführen von LLMs ist vor allem die Speicher‑Datentransferrate der GPU entscheidend; schneller GDDR6X‑Speicher (z. B. RTX 4090) liefert deutlich höhere Token‑Raten als CPU‑Speicher.
- Große Modelle (z. B. GPT‑OSS 120B, 63 GB) passen nicht in den Speicher einer einzelnen GPU; Lösungen sind mehrere 3090‑Karten (NVLink‑unterstützt) oder spezialisierte Workstations wie Nvidia DGX Spark.
- AMD‑Grafikkarten und Apple‑Silicon (MLX) können für kleinere Modelle ebenfalls genutzt werden, jedoch unterstützen viele KI‑Programme primär CUDA.
- Empfohlene Hardware‑Setups:
- Für Modelle ≤ 24 GB: einzelne RTX 3090/4090 oder gebrauchte 3090‑Karten.
- Für sehr große Modelle: Multi‑GPU‑Rigs mit 3090‑Karten oder DGX Spark (weniger Stromverbrauch, aber geringere Token‑Rate).
- Software‑Empfehlungen: LM Studio (einfaches Parameter‑Management, GPU‑Offloading) wird gegenüber Ollama bevorzugt; beide unterstützen Open‑Weights‑Modelle.
- Modell‑Auswahl: Open‑Weights‑Modelle (z. B. Mistral Small 3.2, Qwen 3 4B, GPT‑OSS 120B) können je nach Speicher‑ und Quantisierungsgrad (8‑Bit, 4‑Bit, etc.) optimal eingesetzt werden.
- Quantisierung reduziert Speicherbedarf und erhöht Geschwindigkeit, kann aber bei zu starker Reduktion die Modell‑Qualität beeinträchtigen.
- Praktische Anwendungsbeispiele:
- Lokaler Chatbot mit LM Studio.
- Code‑Generierung, HTML‑Snippets, PDF‑Analyse (RAG) ohne Daten an Cloud‑Dienste zu senden.
- Bild‑ und Vision‑Funktionen (z. B. Gemma 3) für Bild‑Interpretation.
- Grenzen lokaler Modelle: Keine integrierte Internetsuche, daher bei faktischen Fragen schlechtere Ergebnisse im Vergleich zu Cloud‑LLMs.
- Weiterführende Nutzung: Integration in IDEs (VS Code + Continue/Cline), Finetuning, Multi‑GPU‑Serveraufbau – Themen, die in zukünftigen Videos vertieft werden können.
Test mit Mac Studio KI-Server
Ich habe das beschriebene Szenario nun auf meinem [Mac Studio] getestet.
Die net-funtion AG testet zurzeit ähnliche Modelle mit PC-Hardware, Nvidia-GPU und einer Linux-Umgebung. Ich bin auf den Vergleich gespannt.
Aktuell verwende ich mehrheitlich gpt-oss:120b. Dieses benötigt 65 GB Arbeitsspeicher und lässt noch Platz für andere Aufgaben. Heute habe ich erstmalig qwen3-235b getestet. Das ist schon deutlich speicherintensiver mit 112 GB Platzbedarf. So bleibt auf meinem Mac mit 256 GB RAM wenig Platz für andere Aufgaben.
Ist qwen3:235b besser als gpt-oss:120b?
Getestete Modelle
| Modelle | Grösse |
|---|---|
| gpt-oss:120b | 65 GB |
| huihui_ai/qwen3-abliterated:32b | 19 GB |
| huihui_ai/qwen3-abliterated:235b | 112 GB |
Open WebUI
Wie Jan-Keno habe ich einen einzigen Prompt verwendet. [Open WebUI] lässt einen direkten Vergleich von mehreren Modellen in einem Fenster zu. Der HTML‑Code kann sogar in einer Vorschau direkt in Open WebUI beurteilt werden.
Prompt
I need a webpage that outputs the time in Bern, New York and Tokyo
in a beautiful way. Just give me something I can just copy-paste
in a HTML file and run in a browser.
Dark theme, white consolas font, background with stars, blue colors,
each city in a panel with nice animation with mouse over
and a color gradient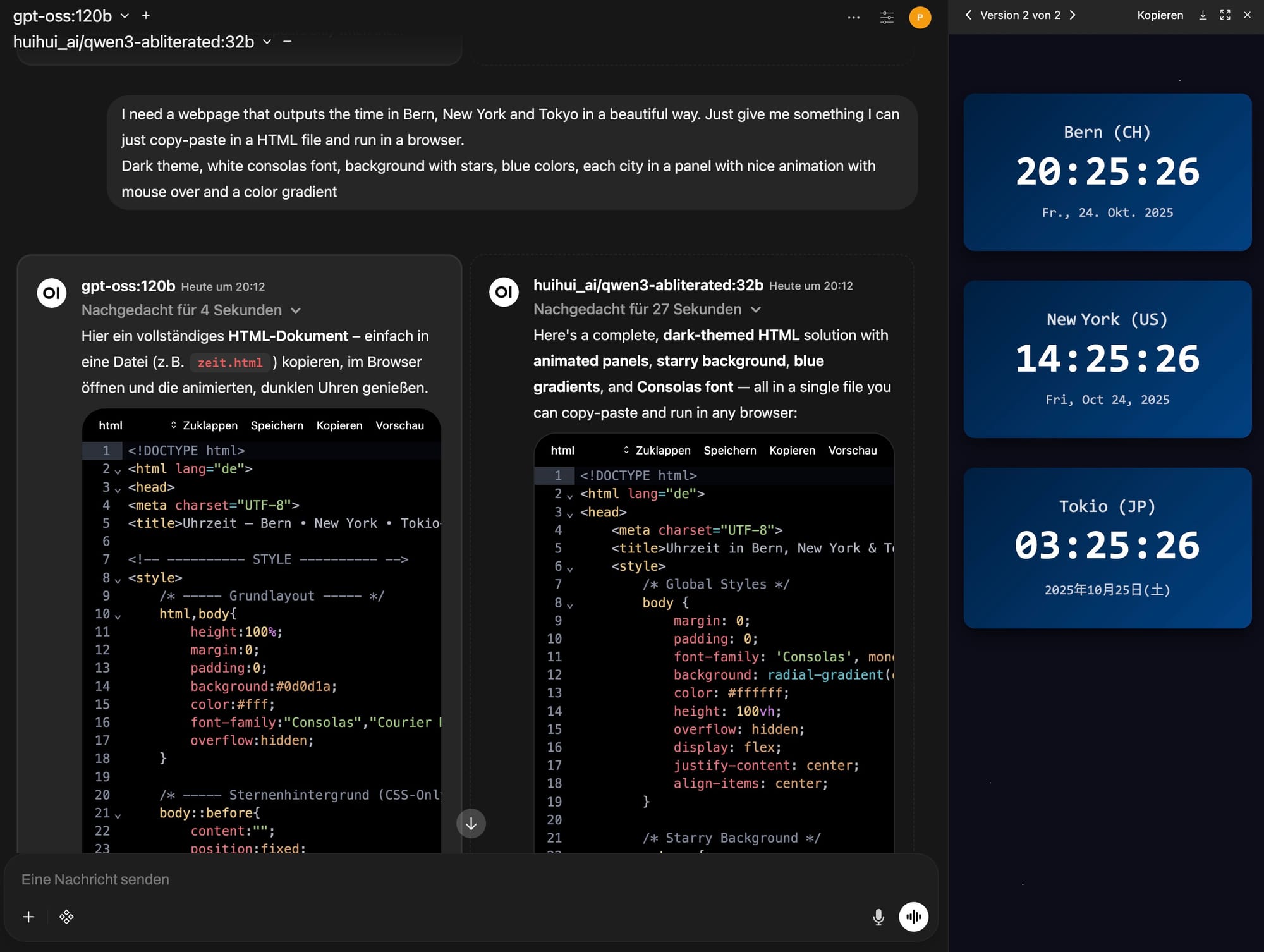
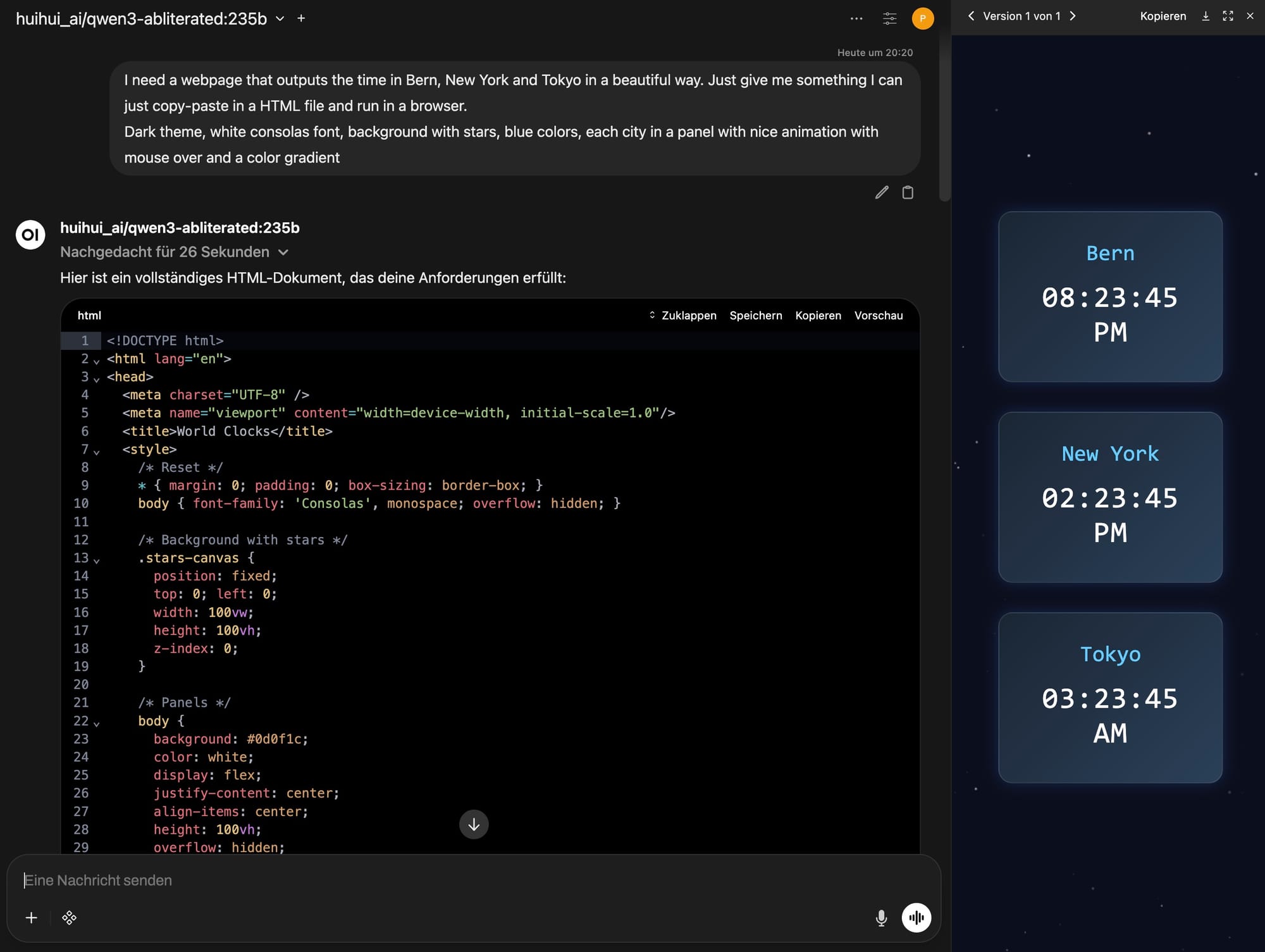
Resultate
Für Ansicht der erzeugten Webseiten auf den entsprechenden link in der Spalte Demo oder den Button klicken. Der Code ist in einem schlanken nginx Container unter UNRAID gehostet [UNRAID Server].
| Modell | Zeit | Demo |
|---|---|---|
| gpt-oss:120b | 61 sec | [gpt-oss:120b] |
| huihui_ai/qwen3-abliterated:32b | 123 sec | [qwen3:32b] |
| huihui_ai/qwen3-abliterated:235b | 101 sec | [qwen3:235b] |