Hardware - Mac Studio Ultra M3
Mac Studio
Apple M3 Ultra Chip mit 28-Core CPU, 60-Core GPU, 32-Core Neural Engine
256 GB gemeinsamer Arbeitsspeicher
2 TB SSD Speicher
Die Zahnarztpraxis Portmann GmbH betreibt den Server und stellt mir diesen zum Gebrauch zur Verfügung 😊.
Es ist die 'kleinste' Ultra Version mit 256 GB Arbeitsspeicher. Das einzige Exemplar an Lager in der Schweiz. 512 GB wäre noch besser, war der GmbH dann finanziell doch zu heftig. Mein Ziel war ein 70B KI-Modell mit etwa 20 tok/sec zu betreiben, das ist mit diesem Modell gerade erfüllt.
Wieso ein Mac für KI? Siehe hier:
https://creativestrategies.com/mac-studio-m3-ultra-ai-workstation-review/
LM Studio
Für erste Tests LM Studio als App installiert auf dem Mac Studio installiert.
Easy peasy.
https://lmstudio.ai/
https://lmstudio.ai/models
- LM Studio ist ähnlich wie Ollama hat aber eine grafische Oberfläche
- Unterstützt auch MLX im Gegensatz zu Ollama (wird dort vermutlich bald eingeführt)
- Kann mit Speculative Decoding ein Hauptmodell mit einem Draft-Modell kombinieren, was die Geschwindigkeit verbessern soll (Google macht das offenbar auch)
- RAG ist direkt im Chat möglich:
Attach Files, upload up to 5 files at a time, with a maximum combined size of 30MB. Supported formats include PDF, DOCX, TXT, and CSV. - Als Frontend verwende ich zurzeit Open WebUI oder Anything LLM
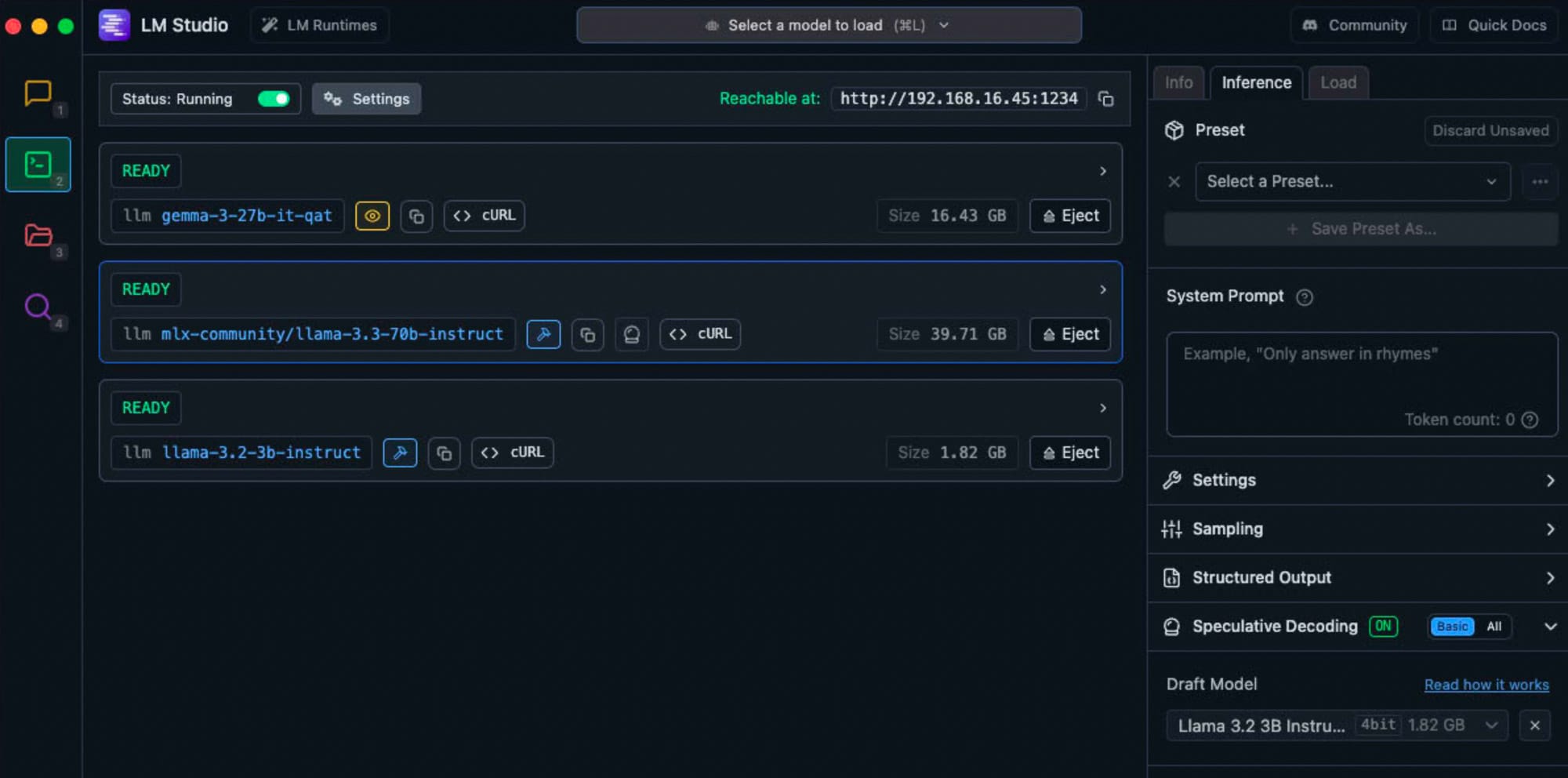
Tests mit LM Studio Chat
Frage:
wie schnell ist ein Gegenstand beim Aufprall,
wenn dieser aus 20 Metern Höhe auf den Boden fällt?
Ich möchte eine Herleitung und das Resultat in m/s und km/h?Wurde von allen unten stehenden Modellen korrekt beantwortet
LM Studio/Interference, mit speculative Decoding
(Hauptmodell, Draft-Modell)
mlx-community/Llama-3.3-70B-Instruct-4bit, draft mlx-community/Llama-3.2-3B-Instruct-4bit
21.16 tok/sec • 507 tokens • 12.24s to first token
• Accepted 320/507 draft tokens (63.1%)Nur ein Modell
mlx-community/Llama-3.3-70B-Instruct-4bit
15.92 tok/sec • 717 tokens • 0.42s to first tokenNur ein Modell
lmstudio-community/gemma-3-12B-it-qat-GGUF, G4
47.45 tok/sec • 813 tokens • 2.10s to first tokenQuellen
KI Vergleich
https://artificialanalysis.ai/
Speculative Decoding
MASSIVELY speed up local AI models with Speculative Decoding in LM Studio
KI-Strategie
The Great AI Migration (smart entrepreneurs are ditching cloud AI and going local