
📑
Paperless-ngx ist ein von der Community unterstütztes Open‑Source Dokumentenmanagementsystem, das physischen Dokumente in ein durchsuchbares Online‑Archiv verwandelt, damit Sie, nun ja, weniger Papier behalten müssen.
Bei mir schlummert das Projekt schon etwa zwei Jahre auf dem Server. Wieso ich es bisher nicht verwendet habe? Mir war der Konfigurationsaufwand dann doch zu gross, zudem ist meine Dokumentenablage über die Jahre gereift und einigermassen organisiert.
Paperless-ngx Blogbeiträge
Paperless-ngx
https://docs.paperless-ngx.com/
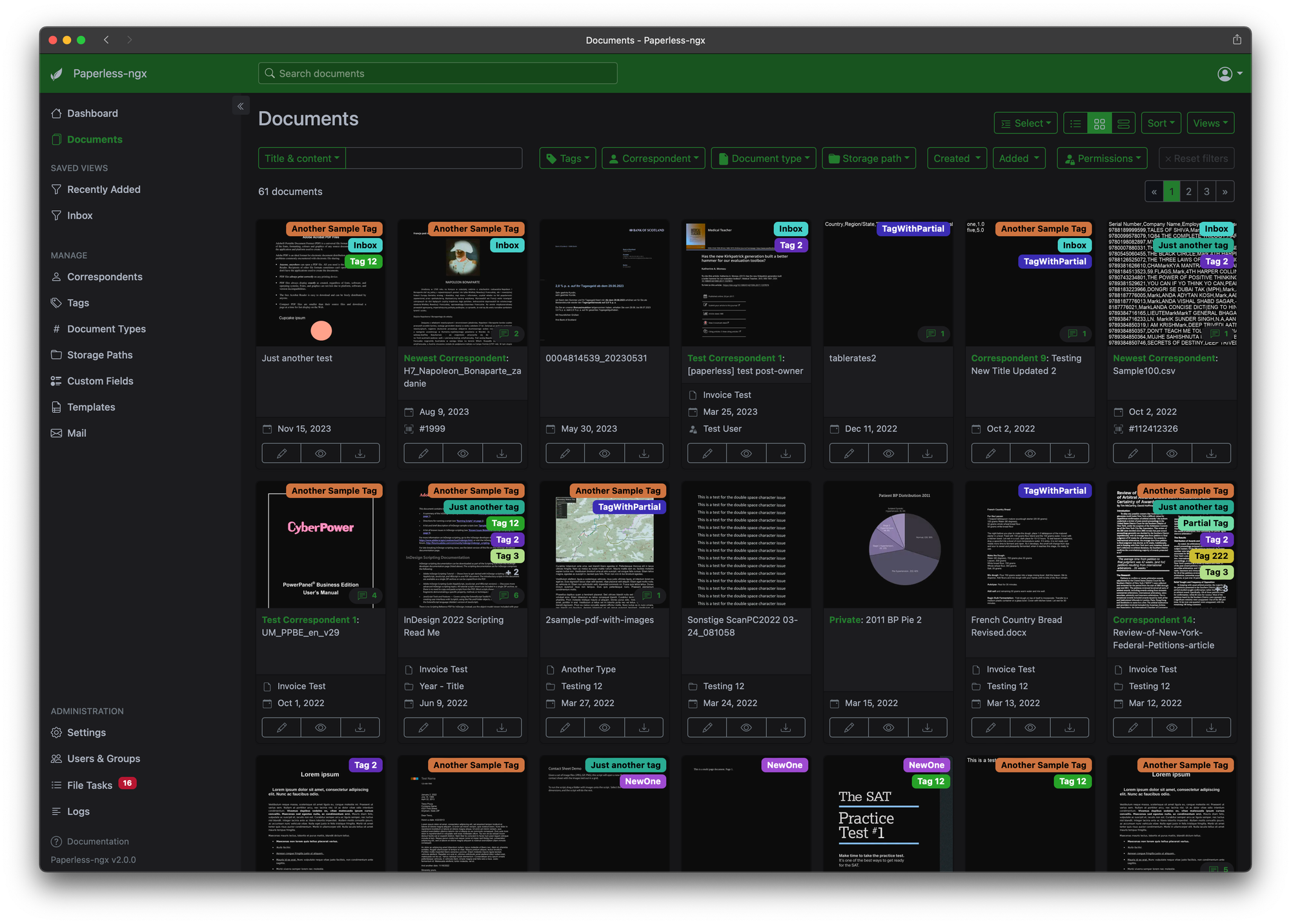
Dokumente
Meine Dokumenten-Verwaltung
- Die Daten liegen auf eigenen Rechnern, externe Sicherungen sind End-to-End verschlüsselt.
- Dokumente sind konsequent nach dem Schema yyyy.mm.tt_beschreibung.pdf benannt. Das mache ich semiautomatisch. Beispielsweise verwende ich seit Jahrzehnten einen Keyexpander, um das Datum im Dateinamen zu setzen (jmt → 2026.04.18). Alles war erhaltenswert ist, hat einen solchen Dateinamen. Erleichtert später die Ausdünnung.
- Strukturierte Ablage, nach Jahr und Rubrik sortiert.
- Eine Datei bleibt, sobald abgelegt, wo sie ist. Es folgt eine Sicherungskaskade mit Versionierung auf externen Laufwerken, in der Nextcloud, auf einer Synology und auch verschlüsselt extern bei Hetzner. Daher soll eine Datei möglichst nicht verschoben werden, da es die Sicherungen unnötig aufbläht.
- Praxisserver mit FileMaker für Patientendokumentation. Dieser läuft seit Jahren stabil und ist für den Praxisbetrieb optimiert. Der Aufwand dieses System zu erweitern, ist mir zu gross und macht keinen Sinn, wenn es schon eine ausgereifte Open-Source Lösung gibt.
Was mir fehlt
- Automatische Verarbeitung mit:
Inhaltserkennung, Dokumentbenennung, Ablage, Schlüsselworten.
Ziele
- Erhalt der digitalen Souveränität
- Eigener Server für Datenablage
- Datenverarbeitung ausschliesslich mit lokalen KI-Modellen
- Automatisierte Erfassung von Bild- und Textdaten als Grundlage für RAG-basierte Wissensdatenbanken und intelligente Auswertungen mit KI
Tools
Damit Paperless zuverlässig funktioniert ist die Datenqualität entscheidend. Sonst heisst es schnell einmal 'Garbage in, Garbage out'.
Diese Komponenten, welche ich regelmässig verwende, sind für den Workflow mit Paperless vorgesehen:
Wieso nicht eine Online-KI in der Cloud verwenden
Exemplarisch für Google:
- Bei Google werden die Eingaben standardmäßig dazu verwendet, die Modelle zu verbessern
- Ein Teil der Unterhaltungen wird von Prüfern gelesen
- Die Chats werden im Google-Konto gespeichert, wenn dies nicht expliziert deaktiviert ist
- Bei Google und anderen Anbietern gibt es Enterprise-Versionen mit strengeren Regeln, der US-CLOUD-Act greift aber trotzdem
