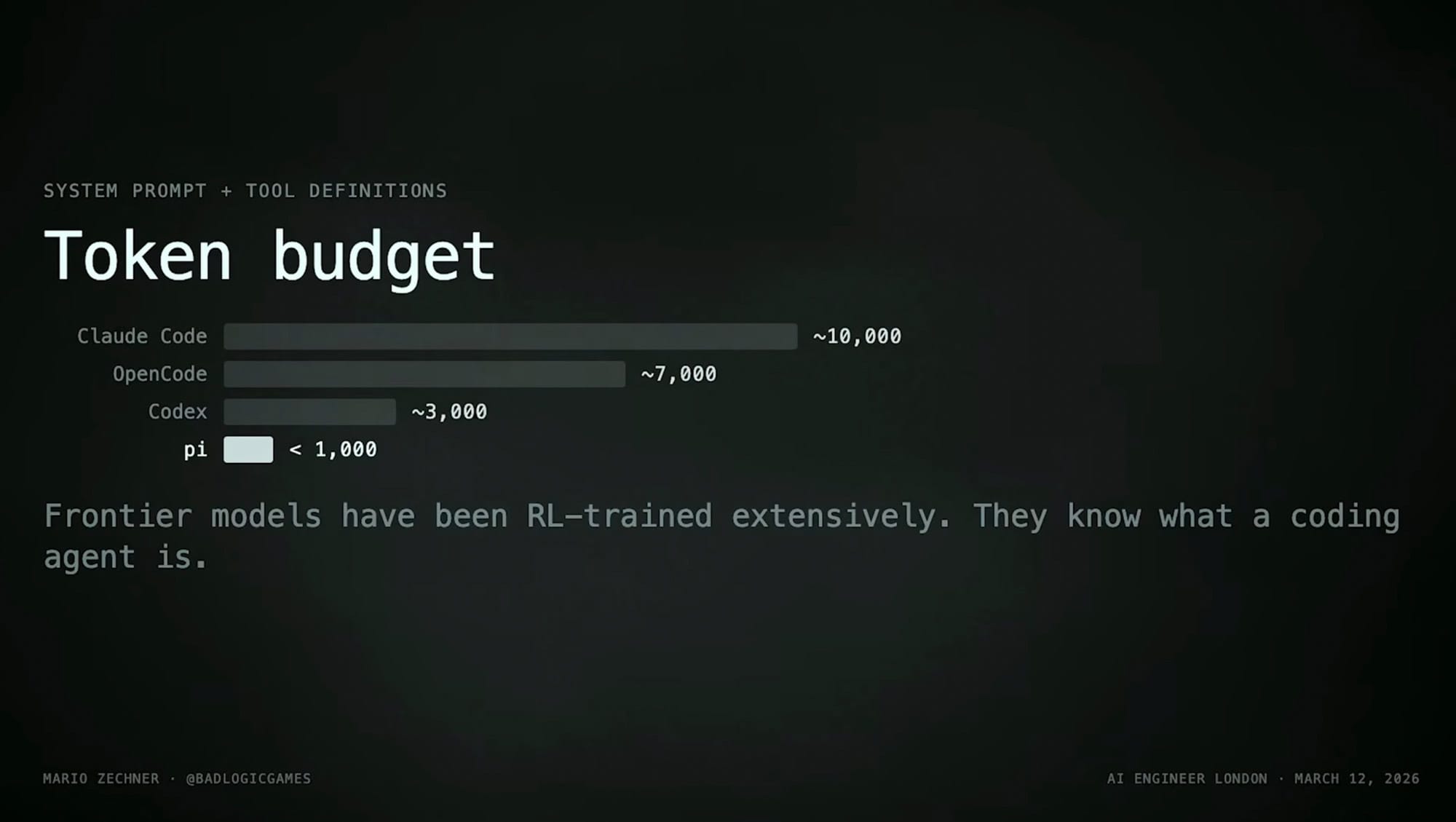
Nach diversen Tests und Recherchen verwende ich den gleichen Agenten und das gleiche Modell wie Donato: Pi Coding Agent und Qwen3.6-35B-A3B-Q8. Interessant, dass wir mit sehr unterschiedlicher Hardware zum selben Ergebnis kommen.
Pi Coding Agent
- Schlank, aber erweiterbar
- Sehr mächtig mit dem Bash-Tool
- geringer 'Tokenverbrauch'
- Viel schneller als Agent Goose oder OpenCode
Aus einem Referat von Mario Zechner am 31.3.2026:
Qwen3.6-35B-A3B-Q8
- Beherrscht Tool Calling, kompatibel mit Pi Coding Agent
- Schnell da MoE (Mixture of Experts)
- Etwas weniger präzise als das Qwen3.6-27B (Dense Model), dafür eben 2-3x schneller
Aus dem Video von Donato:
Hardware
Ich verwende einen Apple Mac Studio, Donato einen framework PC:
https://frame.work/ch/en/desktop
| Feature | AMD „Strix Halo“ (im Video genutzt) | Apple Mac Studio (M3 Ultra) |
|---|---|---|
| Max. Speicherkapazität | 128 GB (im Video) / bis zu 192 GB (neue Max 400er) | 256 GB |
| Speichertyp | LPDDR5X-8000 | LPDDR5X (Custom Apple Silicon) |
| Speicherinterface | 256-bit | Multi-Channel (Ultra-Wide) |
| Theoretische Bandbreite | ~256 GB/s (real ca. 215 GB/s) | 819 GB/s |
| Architektur | AMD Ryzen™ AI Max+ 395 | ARM (28/32-Core CPU + 60/80-Core GPU) |
| Preis | ~ 2500.00 CHF | ~ 4500.00 CHF |
| Lieferfrist | 1 Woche | 2-3 Monate (nur noch 96 GB verfügbar) |
Die Hauptunterschiede im Detail; das meint Gemini
Speicherbandbreite & Inferenz-Geschwindigkeit (Tokens/s)
Bei der lokalen Ausführung von Large Language Models (LLMs) ist fast immer die Speicherbandbreite der absolute Flaschenhals, nicht die Rechenleistung des Grafikchips. Das Modell muss bei jedem Token komplett durch den Speicher geschleust werden.
- Mac Studio (M3 Ultra): Mit atemberaubenden 819 GB/s schlägt der M3 Ultra das AMD-System um das Vierfache. Die Daten können weitaus schneller zur GPU gestreamt werden können.
- Strix Halo: Die 256 GB/s sind für ein klassisches kompaktes Desktop-System phänomenal. Im Video sieht man beispielsweise, dass das Beantworten komplexerer Aufgaben im Benchmark einige Minuten dauern kann.
Speicherkapazität
- Mac Studio: Mit 256 GB Unified Memory lässt sich fast der gesamte RAM als Grafikspeicher (VRAM) deklarieren. Damit lassen sich extrem mächtige Modelle mit weit über 100 Milliarden Parametern lokal ausführen.
- Strix Halo: Das im Video gezeigte Framework-System besitzt 128 GB. AMD erlaubt es zwar im BIOS, fast den gesamten Speicher (bis zu ca. 115 GB) der integrierten Grafikkarte zuzuweisen, wodurch man für einen Bruchteil des Apple-Preises sehr grosse Modelle laden kann, die auf einer normalen Nvidia RTX 4090 (24 GB VRAM) sofort abstürzen würden – allerdings eben mit geringerer Generierungsgeschwindigkeit.
Fazit
Wenn es um die maximale Geschwindigkeit (Tokens/s) und den grössten RAM-Pool für gigantische Modelle geht, ist der Mac Studio M3 Ultra mit 819 GB/s der klare König. Das Strix-Halo-System ist hingegen die Budget-Alternative für die x86-Welt. Es kann dank des grossen geteilten Speichers riesige KI-Modelle laden, die auf normalen PCs unmöglich sind, transportiert sie aber deutlich langsamer als die teurere Apple-Konkurrenz.
Video
Episode 1 einer Serie über das Erstellen und Betreiben von KI‑Agenten auf lokaler AMD‑Hardware. Diese Episode behandelt, wie Coding‑Agents funktionieren, welche Sicherheitsrisiken sie einführen und einen praktischen Vergleich zweier Coding‑Agents, pi und opencode, die auf dem Strix Halo und dem Radeon R9700 AI PRO laufen, unter Verwendung von Qwen 3.6‑Quantisierungen und llama.cpp.
Coding‑Agents basieren unabhängig davon, welchen man wählt, auf denselben Kernprinzipien: einer Kontrollschleife um das LLM, die den Kontext verwaltet, Werkzeuge für Dateizugriff und Shell‑Ausführung bereitstellt, den Sitzungszustand handhabt und optional Sub‑Agents erzeugt. Die Hauptunterschiede zwischen den Agents liegen in ihrer Philosophie bezüglich der Kontextgrösse und dem, was sie standardmässig bieten versus dem, was man selbst konfiguriert. Wenn das LLM auf lokaler Hardware statt in einem Rechenzentrum läuft, sind Kontextlänge und Token‑Durchsatz wichtiger, was bestimmt, welches Agent‑Design besser passt.
Die Episode behandelt zudem die Sicherheitsseite: Prompt‑Injection über nicht vertrauenswürdige Datenquellen, den potenziellen Schaden (Blast Radius) und wie Sandboxing mittels bubblewrap unter Linux oder Docker‑Containern das Risiko reduzieren kann. Abschliessend gibt es ein Benchmark‑Projekt basierend auf einer angepassten Version von SWE‑bench mini, das pi bei 50 kuratierten Software‑Engineering‑Aufgaben evaluiert, wobei Modell‑Quantisierungen verwendet werden, die auf dem Strix Halo und dem R9700 passen.
Diese Serie wirdvon AMD unterstützt.
Links aus dem Video
https://strix-halo-toolboxes.com/#config
Benchmarks: https://pi-local-coding-bench.dev/
Strix Halo Toolboxes & Guides: https://strix-halo-toolboxes.com
Building a Coding Agent from Scratch: https://sebastianraschka.com
Pi Coding Agent: https://pi.dev
Opencode: https://opencode.ai
LLM Chronicles – ReAct Framework Episode: https://llm-chronicles.com
LLM Chronicles – Prompt Injection & LLM Security: https://llm-chronicles.com
Die Zusammenfassung wurde mithilfe von KI‑Tools erstellt. Web Clipper → Obsidian → Copilot, unter lokaler Verwendung von gpt‑oss:120b auf einem Mac Studio.
YouTube hat kürzlich die Codierung geändert, der bisherige Code für das Transkript funktioniert nicht mehr. Diesen habe ich nun angepasst. Siehe hier:
Transkript
Einführung
- Serie über lokale KI‑Agenten, Aufbau, Ausführung und Anpassung von Agentic Workflows auf lokaler Hardware.
- Kostendruck durch teure LLMs in Rechenzentren; Nutzungspreise steigen bei allgemeiner Compute‑Knappheit.
- Verfügbarkeit leistungsfähiger GPUs ermöglicht mittelgrosse Modelle lokal zu betreiben.
- Neue Modellfamilien (z.B. Quen 3.6 ) sind speziell für agentische Anwendungsfälle optimiert.
- Kombination dieser Faktoren macht lokale LLMs praktisch einsetzbar.
Aufbau der Episode
- Überblick über verschiedene Abschnitte, Möglichkeit zum Springen.
- Ziel: Funktionsweise von Coding Agents erklären.
- Viele Optionen, aber gleiche Grundprinzipien; Verständnis erleichtert Auswahl.
- Vorstellung der genutzten Hardware (Strix, Halo, R9700 AI Pro).
- Praktische Codierungsaufgaben mit PI‑Coding‑Agent und Open‑Code, Vergleich von Ergebnis, Geschwindigkeit, Tokenverbrauch.
- Benchmark‑Projekt zur Leistungsbewertung verschiedener LLMs auf lokaler Hardware.
Dank an AMD
- AMD sponsert das Projekt, stellt Ressourcen bereit.
- Ziel: Zeigen, was mit AMD‑GPUs und KI möglich ist; Community zum Experimentieren motivieren.
Funktionsweise von Coding Agents
- Viele Agenten, meist gleiche Arbeitsweise; Unterschied liegt in Minimal‑ vs. Vollausstattung und Anpassbarkeit.
- Eigenen Agenten bauen fördert Verständnis (Referenz: Artikel von Sebastian Rashka).
- Agent = LLM + Harness (Steuerungsschleife) zur Kontextverwaltung, Zustandsverfolgung und Tool‑Integration.
- Harness sammelt Projekt‑Kontext (Git‑Status, Dateistruktur) und fügt ihn in Prompt ein.
- Tools (Datei‑I/O, Shell, Web, MCP‑Server) geben dem LLM Handlungsfähigkeit.
- Kontextmanagement durch Kürzen von Ausgaben und periodisches Zusammenfassen verhindert Fensterüberlauf.
- Sitzungs‑Management ermöglicht Fortsetzen, Forken oder Zurückrollen von Gesprächen.
- Sub‑Agents können parallel im Hintergrund laufen.
- Unterschiedliche Implementierungen: Cloud‑Code/Open‑Code (umfangreich, höhere Kosten) vs. PI‑Coding‑Agent (minimal, anpassbar).
- Lokale Hardware erfordert kürzere Kontextfenster und effizientere Nutzung.
Sicherheitsrisiken & Sandboxing
- Coding Agents benötigen umfangreiche Berechtigungen (Shell, Dateisystem, Internet); potenziell gefährlich.
- Gefahr von Prompt‑Injection bei untrusted Eingaben; Angreifer können Kontrolle übernehmen.
- Beispiel: Fehlfunktion eines Agenten löschte komplette Produktionsdatenbank (April 2026).
- Mensch‑in‑der‑Schleife reduziert Risiko, ist aber bei vielen Aktionen mühsam (Approval Fatigue).
- Sandboxing als Kompromiss: Beschränkung auf Projektordner, Prüfung jeder Tool‑Ausführung gegen Nutzerregeln.
- OS‑Level Sandbox (Sandbox‑XPC, Bubblewrap) oder Container (Docker) erhöhen Isolation.
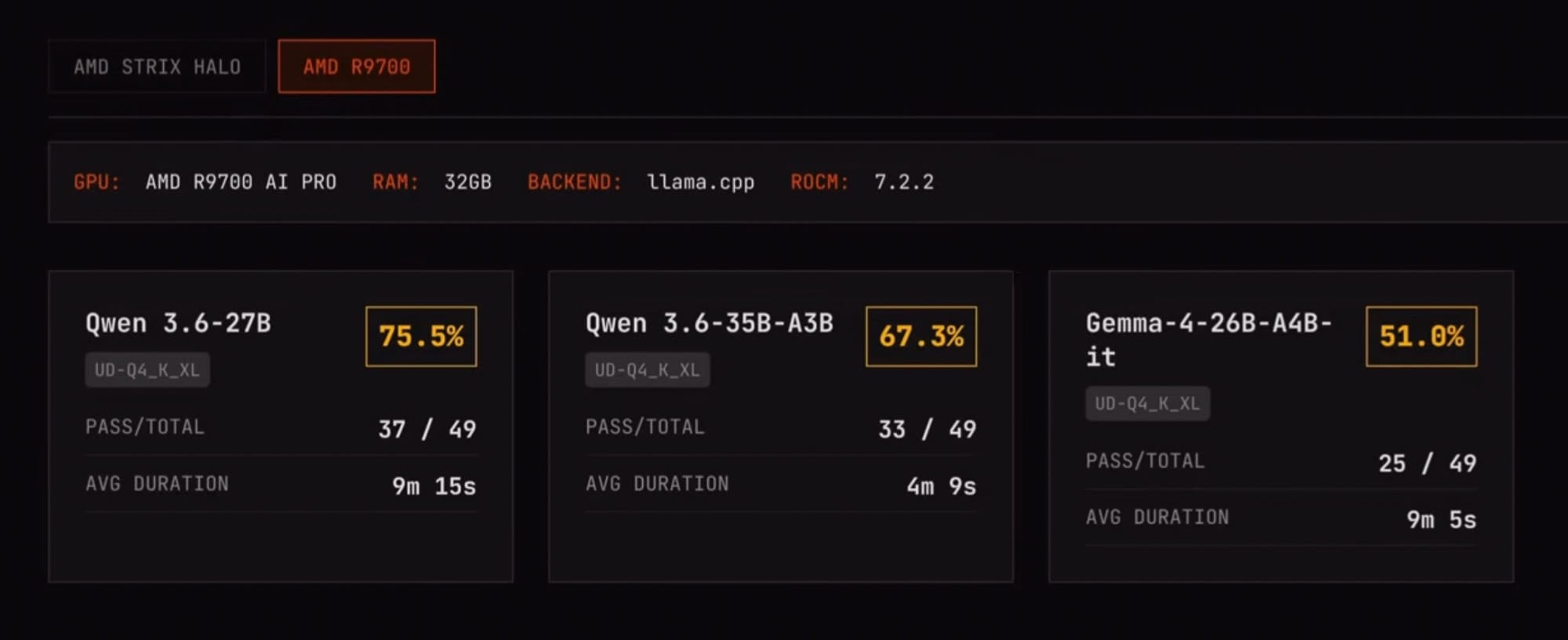
Die Hardware (Strix Halo / R9700)
- Verfügbare GPUs bestimmen Modell‑ und Quantisierungswahl (z.B. Quen 3.6 six 8‑Bit auf Strix).
- Auch einzelne R9700 AI Pro mit 32 GB VRAM reicht für leistungsfähige Quantisierungen.
- Nutzung beliebiger Inferenz‑Engines (LlamaCPP, Ollama, LM Studio) möglich; OS‑unabhängig.
- Empfehlung: LLMs auf Remote‑Server laufen lassen, Port weiterleiten, um Workstation zu entlasten.
Pi Coding Agent
- Installation mit einem einzigen Befehl; Konfiguration über
models.json(Provider‑Name z.B. llama‑cpp). - Nutzung von Quen 3.6 35B Modell in Q8K‑XL Quantisierung auf Strix.
- Demonstration: Update eines Toolboxes von Version 7.2.2 zu 7.2.3 inkl. Anpassung aller Referenzen.
- Agent nutzt minimale Tools (Datei‑I/O, Shell) und hält Kontext klein.
- Sandbox‑Extension konfiguriert Zugriff auf Netzwerk (nur GitHub), Dateisystem (Arbeitsverzeichnis, Temp) und blockiert sensible Pfade.
- Ergebnis: 19 k Tokens Eingabe, 6 k Tokens Ausgabe (~25 k Tokens gesamt) für die Aufgabe.
Opencode
- Open‑Code ist voll ausgestatteter Agent mit umfangreichem Permission‑Model (Granulare Genehmigungen für Shell‑Befehle und Dateizugriff).
- Konfiguration ähnlich wie PI, aber grössere System‑Prompts führen zu höherem Tokenverbrauch.
- Demonstration derselben Toolbox‑Aktualisierung: Plan‑Modus, ausführliche Anweisungen, UI‑Anzeige von Änderungen.
- Tokenverbrauch deutlich höher (≈39 k Tokens) und langsamer aufgrund grösserer Kontextgrösse.
Benchmarks (SWE‑bench mini)
- Projekt benchmarkt Modell‑Quantisierungen auf Strix und R9700 hinsichtlich Erfolgsrate und Geschwindigkeit.
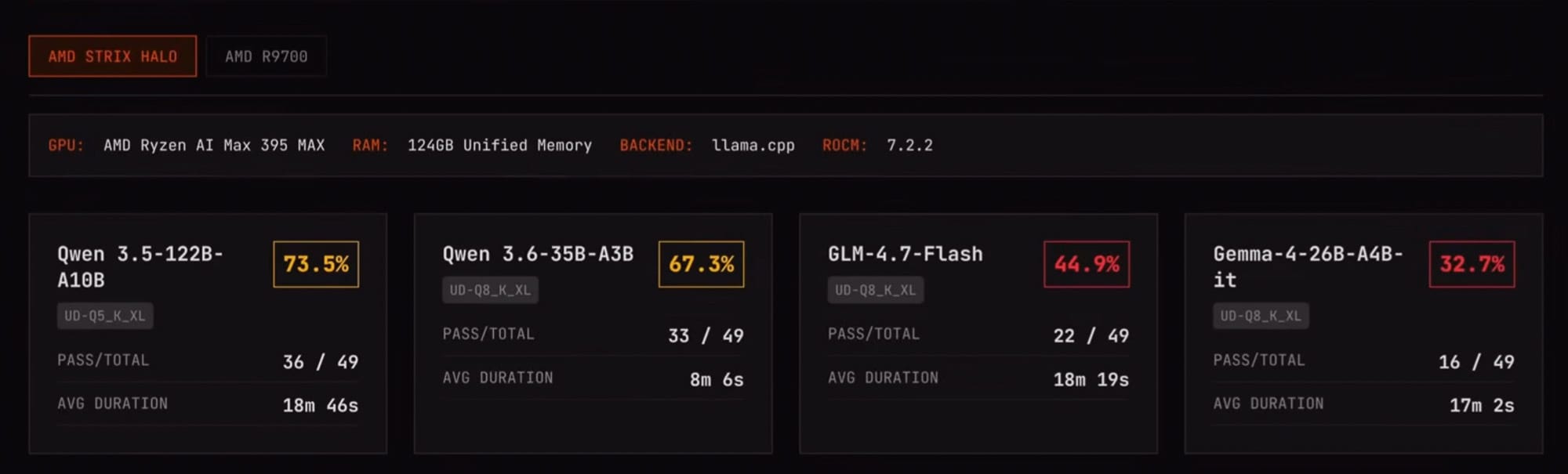
- PI‑Agent mit Quen 3.6 six erreicht 67 % Erfolg, durchschnittlich 8 min pro Aufgabe auf Strix.
- Kleinere Modelle (3.5 B) haben höhere Erfolgsrate aber sind langsamer.
- Auf R9700 gleiche Quantisierung halbiert die Laufzeit (~4 min); dichte 27 B Version erreicht ähnliche Erfolgsrate bei ~9 min.
- Multi‑Token Prediction (MTP) reduziert Dauer weiter (auf Strix auf 5 min 36 s, auf R9700 auf 6 min 9 s).
- Hinweis auf Benchmark‑Limitationen: Datenkontamination, fehlende Internet-/Human‑Feedback‑Interaktion.
Fazit
- Nächste Episode behandelt lokale Agenten für Deep Research, parallele Sub‑Agents und sichere Mailbox‑Integration.